
This post is divided into two parts: the PRE, which I composed before the NVivo session, and the POST, reflecting on the experience after its conclusion.
PRE: Preparing for my final NVivo session
As the semester wraps up, I’m feeling the weight of a long term. Usually, I can shake off the tiredness after a busy year of teaching, but this time it’s different. It feels like all those months have finally caught up with me. Now, I’m looking at my last teaching session for the term, and it’s all about NVivo for a small number of grad students. To be honest, teaching NVivo is tough for me. It’s not just because the software’s got a lot of bells and whistles. It’s more like trying to figure out what comes first – the chicken or the egg? What do you teach first?

With this upcoming session, I keep thinking about how important it is to start on solid ground. If the basics aren’t strong, everything else kind of wobbles, and that’s making me nervous. I often think in a one shot session that faculty want those bells and whistles that I mentioned earlier. This summer, I’ve got big plans to shake up how I teach qualitative data analysis, basically rebuilding my approach from the ground up. Tomorrow, I’m testing out new stuff for a module, and yeah, it’s kind of freaking me out.
The problem with teaching NVivo
I often get asked to come to classes and give the lowdown on NVivo. Sometimes I’ve got an hour and a half, other times they expect miracles in 30 minutes, and then there are the marathon three-hour sessions (like tomorrow). Let me tell you, no matter how much time you’ve got, it’s never enough to really get into NVivo. In 30 minutes? Forget about it. Even in three hours, we’re just scratching the surface. Why? Because getting NVivo right means building a solid base, and that can get a bit yawn-worthy. You’ve got to get all your ducks in a row with your data before you even think about analyzing it.
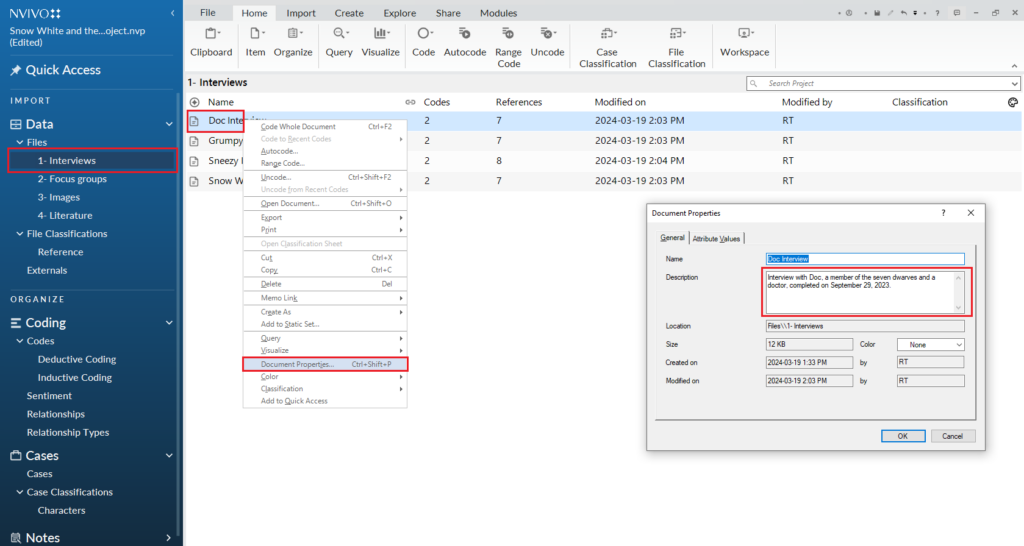
So, for tomorrow’s session, I’m zeroing in on getting set up properly. I’m using a dataset I put together with ChatGPT, based on Snow White and the Seven Dwarves (yeah, really). I’ve talked about it on the blog before, so I won’t bore you with the details here.
Teaching NVivo in 3 hours
Here’s the game plan for tomorrow:
- The 30-minute presentation about NVivo
- 30 minutes of downloading and importing the files into NVivo (hopefully I can shave time out of this part), files include:
- Interviews
- Focus groups
- Literature
- Images
- Case classifications
- 30 minutes of setting up the folder and file properties
- 30 minutes of setting up codes (I have a deductive coding structure, but I use this only to show students how to CREATE and nest codes)
- 1 hour of the students coding the data and running some simple queries
The main idea here is making sure everyone knows how crucial it is to start their project right. I’ve seen too many people trip up because their foundation was shaky. Getting that foundation right is what tomorrow is all about, and it’s the big message I want to hammer home with my new approach to NVivo foundations.
POST: So how did the NVivo session go?
Reflecting on the recent session, I’m pleased to report it was a success.
Whenever I start a workshop, I engage participants with a set of questions relevant to the upcoming content. I inquire about their familiarity with NVivo, and their hands-on experience with the software. This preliminary check-in serves as a valuable tool, allowing me to tailor my presentation dynamically, according to the initial feedback. Interestingly, in yesterday’s group, most people had some prior experience with NVivo.
While students having experience with the software does help, I was worried that my foundational approach to teaching this session might be too basic. Foundational teaching is important to me, I’ve written about this before. However, it quickly became clear that my foundational approach to NVivo connected with the students.
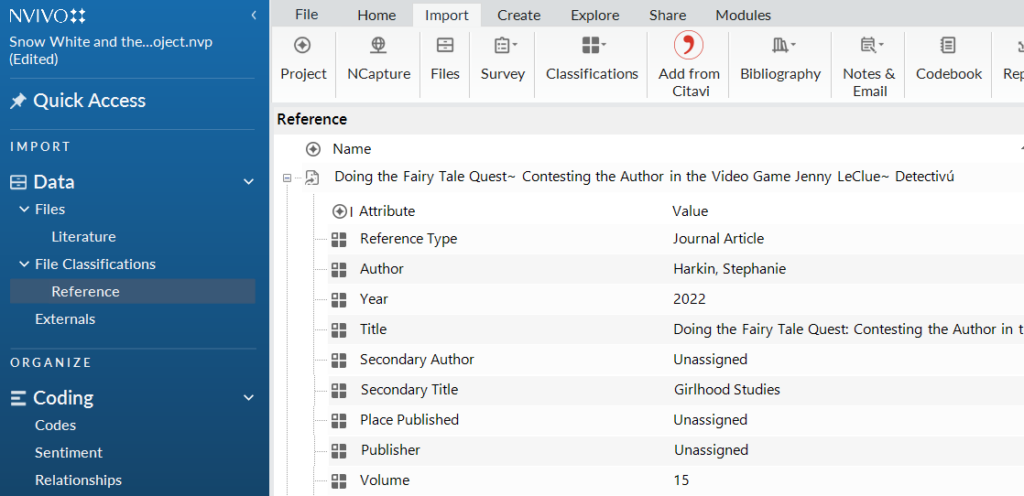
I knew the session was effective when I heard an audible gasp from the audience as I showed them two ways to import literature into the software. The first, adding your articles as .PDF file type. The second, (and arguably better way) is importing your literature as a “Bibliography” using a .RIS filetype. By importing this way, it gives you a “Reference File Classification”. This file classification includes bibliographic information such as date of publication, author, volume/issue, etc.
The fundamental message
The core takeaway I emphasized during the session was clear and straightforward: Prior planning is crucial when engaging with qualitative data analysis (QDA) tools such as NVivo. One should not rely on QDA software to compensate for a lack of initial project design.
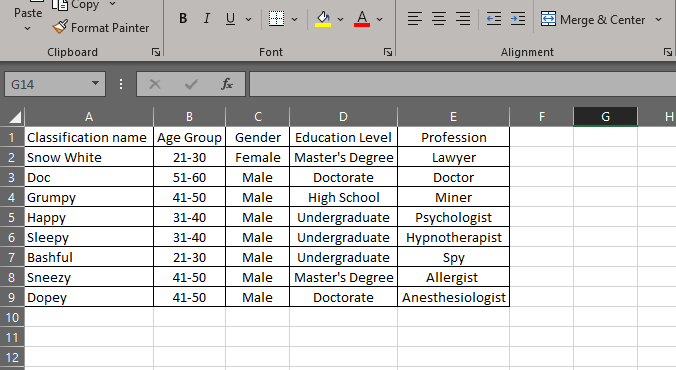
This includes gathering all pertinent participant details—such as age, gender, profession, and education level—that may be relevant to your analysis from the outset. It’s a challenging task to retrieve this information retroactively. By having this data from the beginning, you can construct classification sheets that are not only easier to clean and organize but also significantly enhance the efficacy of your research.
Wrapping up
The session concluded on a high note, a welcomed outcome given the nearly 10 hours of preparation I dedicated to it. This workshop was instrumental in laying the groundwork for a refreshed NVivo Fundamentals module on Brightspace. It was wonderful to see that students from basic to intermediate levels appreciated the foundational focus of the session. As I’ve consistently said, a solid foundation is required before delving into more advanced concepts. The content and framework I created for this NVivo workshop reaffirmed a valuable lesson: a well-prepared foundation is key to effective learning and teaching.